
5주차
Ch. 06 비지도 학습
ㄴ 06-1 군집 알고리즘
ㄴ 06-2 k-평균
ㄴ 06-3 주성분 분석
06-1 군집 알고리즘
드디어..! 드디어 비지도 학습이다 우하하
사실 모든 데이터에 타깃이 있진 않잖아요..?
내가 머라고하지 않아도. 스스로. 알아서. 자기주도학습을 하다니
정말 awesome한 모델이잖아...🫰


이번엔 과일 사진 데이터를 사용하는데,
왼쪽의 넘파이 배열이 오른쪽의 사과를 저장한 것이라는 점....
일단 난 사진을 배열로 저장한다는 것부터 몰.랐.어. (...)
✅맷플롯립의 imshow() : 넘파이 배열로 저장된 이미지 출력
> cmap : 'gray' → 흑백 이미지
cmap : 'gray_r' → 흑백 반전
⚠️넘파이 배열에 저장될 때에는 반전되어 저장됨
> gray_r로 설정했을 때 원래의 흑백 이미지로 출력

✅subplots(행, 열) : 여러 개의 그래프를 쌓을 수 있도록 도와줌
다음으로 사과의 픽셀 평균값을 계산 해보앗어요

응..?
이게뭐지...
잘 모루겟떠염(;;)

그래서 히스토그램으로 보기로 햇어요..
바나나의 평균값은 수가 작은 쪽에 모여 있고
사과랑 파인애플은 높은 쪽에 좀 겹쳐있다는 점을 히스토그램 덕분에 잘 알게되었습니다..

또 다른 방법도 잇어요..
제 그래프가 책이랑 좀 다르게 나오긴 햇지만...
값의 분포가 보이는 느낌..?!

평균으로 이미지를 출력해봤을때!!!
뭔지 대충 알겟는게 너무 웃김 아하하
abs_diff = np.abs(fruits - apple_mean)
abs_mean = np.mean(abs_diff, axis=(1,2))
print(abs_mean.shape)
apple_index = np.argsort(abs_mean)[:100]
fig, axs = plt.subplots(10, 10, figsize=(10,10))
for i in range(10):
for j in range(10):
axs[i, j].imshow(fruits[apple_index[i*10 + j]], cmap='gray_r')
axs[i, j].axis('off')
plt.show()
사과의 평균값과 가장 비슷한 사진 100개를 뽑았더니..
놀랍게도 정말 사과만 100개가 나왔다.
너 진짜 쩌네
✅abs() : 절댓값 계산 ( = np.absolute() )
✅np.argsort() : 큰 순서대로 나열한 인덱스 반환
06-2 k-평균
이번에는 앞이랑 다르게 어떤 과일이 있는지 모르는 채로 평균을 구하는 방법을 알아본다고 하는데.. 흠
이런 경우에 사용하는게 바로 k-평균이라규 함..
✅k-평균 알고리즘
1. 무작위로 k개의 클러스터 중심을 정함
2. 각 샘플에서 가장 가까운 중심을 찾아 해당 클러스터의 샘플로 지정
3. 클러스터에 속한 샘플의 평균값으로 중심 변경
4. 클러스터 중심이 변화가 없을 때까지 반복
흠.
무슨소린지 아시겟는분??
오늘도 구글 슬라이드를 펴보겟습니다.
기본 과제 : k-평균 알고리즘 작동 방식 설명하기

먼저 군집의 중심을 랜덤으로 초기화 합니다.

다음으로는 모든 개체들을 가장 가까운 중심에 할당해줍니다.
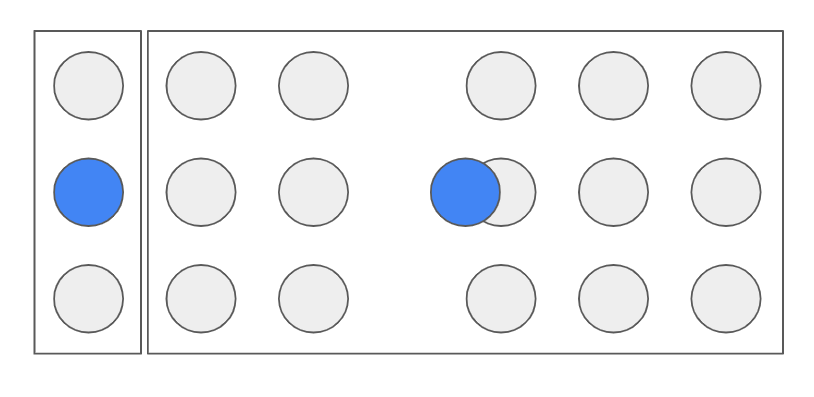
그리고 중심을 군집에 맞게 업데이트 해주고용

업데이트한 중심을 기준으로 다시 개체들을 가장 가까운 중심에 할당해줍니다.
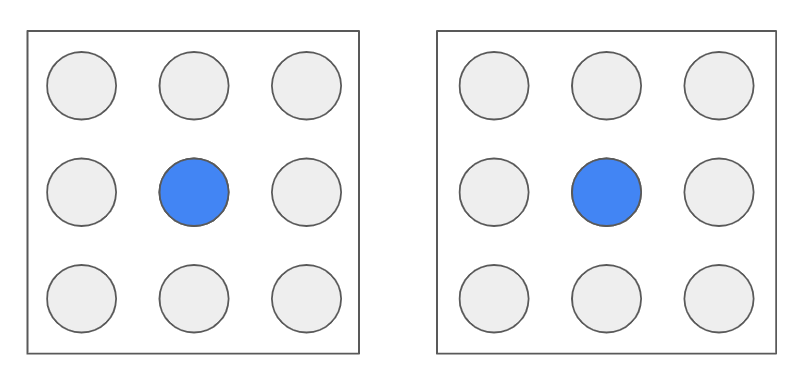
그리고 마지막으로 다시 군집의 중심을 업데이트하면...!!
두 개의 클러스터로 정확히 구별된 결과가 나옵니다.
알고 보면 완전 쩌는 알고리즘이랍니다..
요 멋진 k-평균 알고리즘은 sklearn.cluster 모듈 아래 KMeans 클래스에서 사용할 수 잇대욤.
대신 비지도 학습이기 때문에 fit() 메서드에서 타깃 데이터를 사용하지 않습니다!!
✅sklearn.cluster 모듈 아래의 KMeans : k-평균 알고리즘
⚠️fit() 메서드에서 타깃 데이터를 사용하지 않음!
결과는 객체의 labels_속성에 잘 저장이 되어잇답니다
그래서 어떻게 군집을 형성햇나 한 번 보자고요.



파인애플에만 사과랑 바나나가 좀 섞여 있고,
바나나랑 사과는 잘 구분한 똑똑이네요..
너. 재능잇어.
✅labels_ : 군집된 결과
✅cluster_centers_ : 최종적으로 찾은 클러스터 중심
✅n_iter_ : 알고리즘이 반복한 횟수
k-평균 알고리즘의 단점인 클러스터 개수 지정을 극복하기 위해 최적의 k값을 찾는 방법을 알아봅시다..
먼저 클러스터 중심과 샘플 사이의 거리의 제곱 합을 이너셔라고 하는데,
이너셔의 변화를 관찰하여 최적의 k값을 찾는 방법을 엘보우 방법이라고 한다네여.
클러스터 수를 증가시키면서 이너셔가 감소하는 변화가 확 줄어드는 지점!!! 바로 그 때의 값이 최적의 값이라고 한다네요.
흠.
역시 그래프를 봐야겟어요
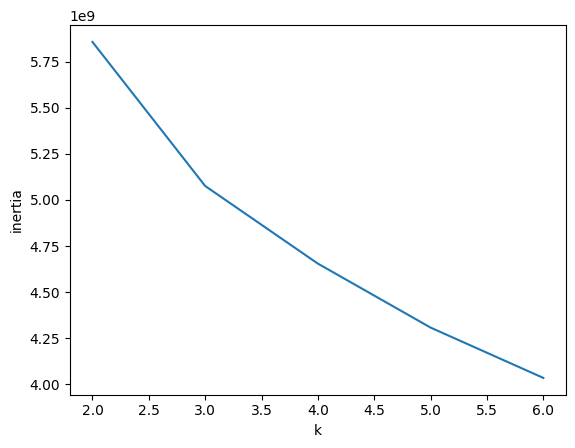
딱 보면 k값을 3으로 지정하면 되겟다 싶네요...
친절한 KMeans 클래스는 이너셔도 자동으로 계산해주기 때문에
잘 부려먹으면 되겟습니다. 후훗.
✅inertia_ : 이너셔
06-3 주성분 분석
주성분 분석...
차원 축소 알고리즘이라니..
핸드폰 256GB를 꽉 채우고 잇는 나같은 맥시멀리스트에게 아주 중요한 알고리즘이겠어요.
주성분 분석은 분산이 큰 방향을 찾는 것이라규 합니다.
주성분은 분포를 가장 잘 나타내는 벡터를 가리키는데,
첫 번째 주성분에 수직이고 분산이 가장 큰 벡터를 두 번째 주성분으로 설정하고...
이렇게 이어나가는 것 같네여.
주성분 분석도 PCA 클래스를 사용할 수 있고, 비지도 학습이기 때문에 fit()함수에서 타깃을 넣지 않아요.
✅sklearn.decomposition 모듈 아래의 PCA : 주성분 분석 알고리즘
> n_components : 주성분의 개수 지정 / 원하는 설명된 분산의 비율 입력
⚠️fit() 메서드에서 타깃 데이터를 사용하지 않음!
✅components_ : 주성분이 저장되어 있음
✅explained_variance_ratio_ : 설명된 분산 비율 (주성분이 원본 데이터의 분산을 얼마나 잘 나타내는지)
✅transform() : 차원 축소
✅inverse_transform() : 특성 복원
PCA로 훈련 데이터의 차원을 축소하면 훈련 속도가 훨씬 빨라지는 효과가 있어욧.
당연히 데이터의 크기가 작아지니까 훈련하는 데에도 오래 안 걸리는거겟죠
데이터의 수가 많아질수록 아주 유용하겟네요...

와 벌써 개강 얼마 안남은거 실화인갘ㅋ
나 학교 안갈래~~~~~
그나마 수강신청 시뮬레이션까지 돌리고 가서 금 공강 사수함..
듀후후.. 듀후후훗...
그래도 학교는 안갈래~~~~~~~~~~💢💢
'Machine Learning' 카테고리의 다른 글
| [혼공머신] 6주차_인공 신경망 / 심층 신경망 / 손실 곡선, 드롭아웃, 모델 저장, 콜백 (1) | 2025.02.23 |
|---|---|
| [혼공머신] 4주차_결정 트리 / 교차 검증 / 앙상블 기법 (2) | 2025.02.09 |
| [혼공머신] 3주차_로지스틱 회귀, 시그모이드, 소프트맥스 / 확률적 경사 하강법 (2) | 2025.01.26 |
| [혼공머신] 2주차_회귀 / 특성 공학 / 변환기(Transformer) (4) | 2025.01.19 |
| [혼공머신] 1주차_훈련, 테스트 셋 / 데이터 전처리 (3) | 2025.01.07 |