
3주차
Ch. 04 다양한 분류 알고리즘
ㄴ 04-1 로지스틱 회귀
ㄴ 04-2 확률적 경사 하강법
04-1 로지스틱 회귀
데이터 준비 과정은 간단히 보자!
타깃 데이터로 species 열, 이외의 5개 열은 입력 데이터로 사용하고,
StandardScaler 클래스를 사용해서 표준화 전처리를 마쳤다.

모델 학습과 점수는 [8]셀에서 확인할 수 있다.
[9]셀에서는 클래스를 출력해보면 정렬된 타깃값이 알파벳 순이라는 점을 알 수 있다.

테스트 셋의 처음 5개의 샘플으로 예측한 값과 그 확률을 확인해보았다.
✅predict_proba() : 클래스별 확률값 반환
✅round()의 decimals : 소수점 자릿수 지정
확률의 각 열은 이전의 알파벳 순으로 정렬된 클래스 순서이다.
아래에는 세 번째 샘플의 이웃을 실제로 출력해본 결과이다.
이웃 세 개 중 2개가 'Perch', 1개가 'Roach' 이므로 위의 확률과 동일하다는 점을 알 수 있다.
로지스틱 회귀는 회귀라는 이름을 가지고 있지만 분류 모델이라고 한다.
또한 선형 방정식을 학습한다는 점! 식으로 나타내면 z = (~가중치 x 특성~) 이런 식이라고 한다.
여기서 z를 0~1 사이의 확률로 만들기 위해 사용하는 것이 시그모이드 함수이다.


시그모이드 함수는 이렇게 생겼다..
그래프를 보면 z값이 커질수록 1에 영원히 가까워지고, z값이 작아질수록 0에 영원히 가까워지는 것을 볼 수 있다.
즉 절대적으로 0과 1사이의 값이라는 것이다.
시그모이드 함수는 딥러닝으로 넘어갔을 때 LSTM이나 GRU의 활성화 함수로도 사용이 된다.
그 때 가서 이게머지.. 하지 않도록 기억해서 나쁠 건 없다.
이제 로지스틱 회귀를 사용해서 이진 분류를 해보자.
먼저 불리언 인덱싱에 대해 간단히 알아보면
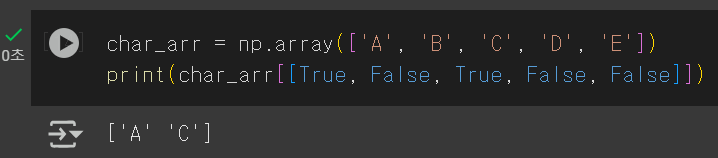
위의 print 식을 보면 True 인 값만 출력된 것을 볼 수 있다.
이걸 활용해서 이전의 생선 7종 데이터를 Bream, Smelt 행만 남겼다.
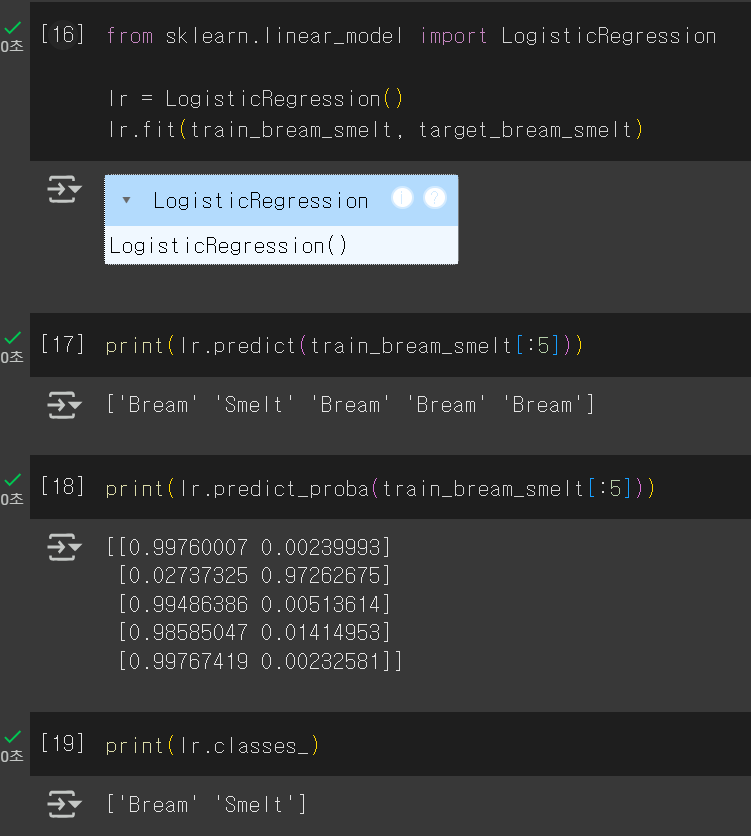
인덱싱한 데이터로 훈련시키고 예측값과 확률까지 확인할 수 있다.
클래스 두 개만 인덱싱 했기 때문에 확률도 2개의 열만 나오는 것을 확인할 수 있다.
그리고 클래스를 출력해서 각 열이 어떤 클래스의 확률인지도 확인이 가능하다.
어차피 이진 분류이고 알파벳 순이라는 것을 아니까 출력하지 않아도 생각해보면 되겠지만...
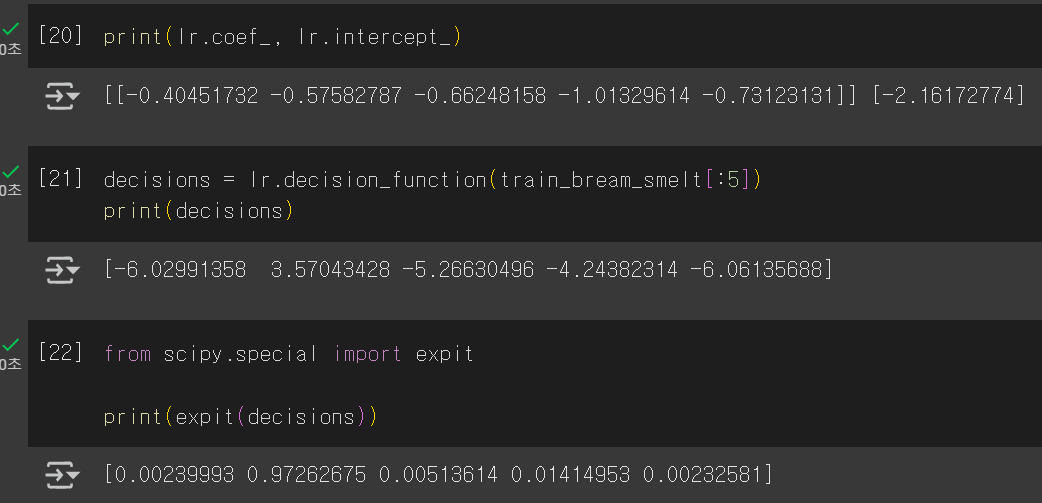
로지스틱 회귀가 학습한 계수도 출력해볼 수 있다. 선형 회귀랑 비슷하다는걸 다시 한 번 느낄 수 있다..
[21]셀은 z값을 출력한 것이고, [22]셀은 z값에 시그모이드 함수를 적용시켜서 확률로 변환한 결과이다.
✅decision_function() : z값 출력
✅scipy 라이브러리의 expit() : 시그모이드 함수
이제 다중 분류를 해보자.
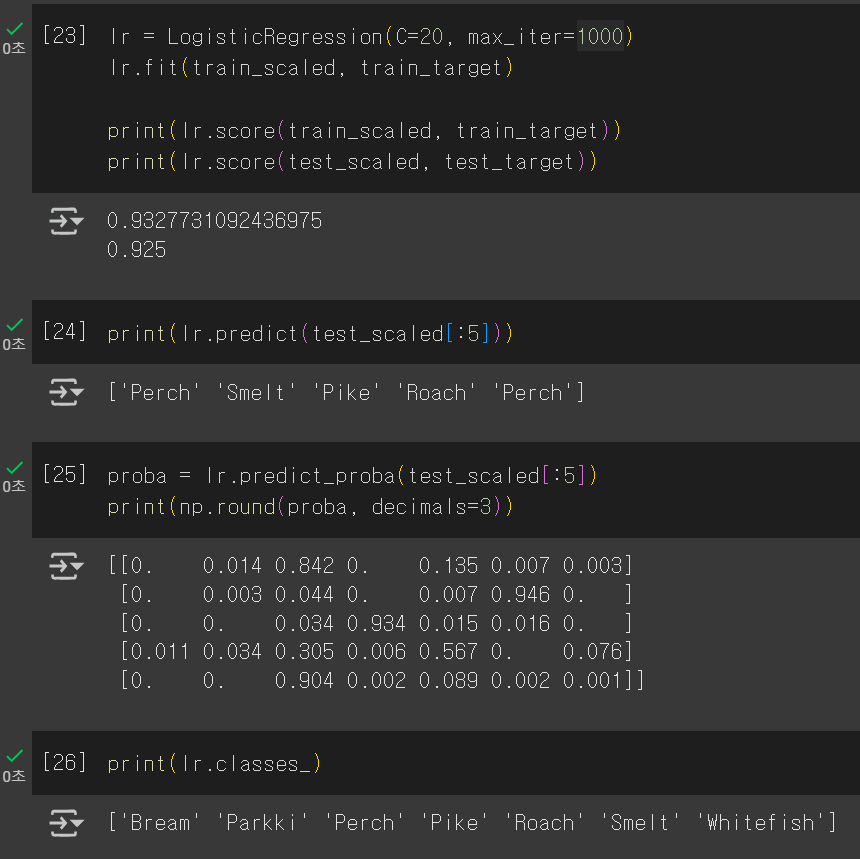
이전과 내용은 동일하다.
다른 점으로는 매개변수가 생겼다는 점..?
✅C : 규제 조절 > 값이 클수록 정규화 효과 약해짐
✅max_iter : 에포크 설정
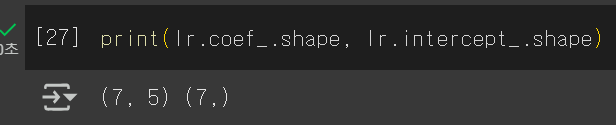
학습한 모델의 계수를 확인해보면
각 클래스마다 z값을 계산한다는 점을 알아낼 수 있다.
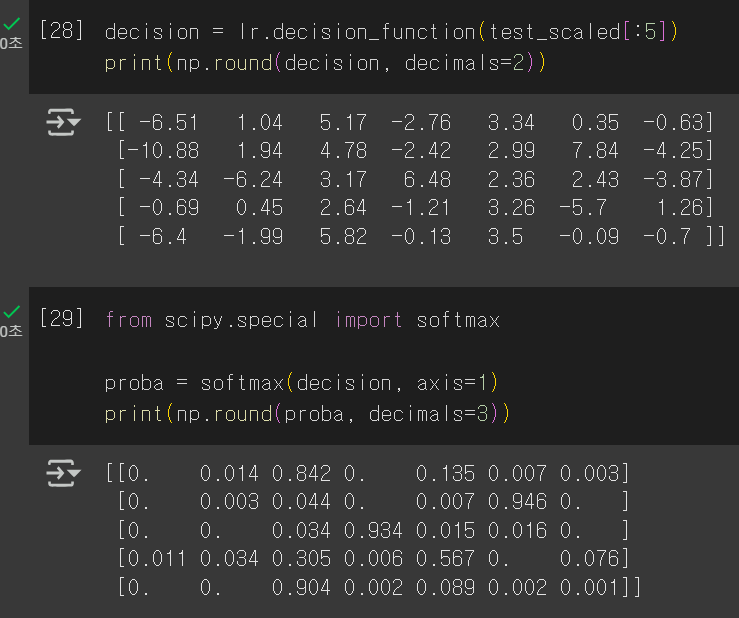
다중분류에서의 z값과 확률도 확인할 수 있다.
여기서 이진분류와 다른 점은 시그모이드 함수가 아닌 소프트맥스 함수를 사용한다는 점이다.
소프트맥스도 활성화 함수로 많이 사용된다.
04-2 확률적 경사 하강법
✅점진적 학습 : 새로운 데이터가 추가되었을 때 새로운 데이터에 대해서만 추가로 훈련
> 대표적인 알고리즘으로 확률적 경사 하강법이 있다!
✅확률적 경사 하강법
훈련 세트를 이용하여 가장 가파른 길을 찾음
but. 딱 하나의 샘플을 랜덤하게 골라 가장 가파른 길을 찾음
이걸 모든 샘플 사용해서 손실이 원하는 만큼 떨어질 때 까지 계속 시도…
이제 확률적 경사 하강법 활용 Go Go
데이터 준비와 전처리는 이전과 동일하다.
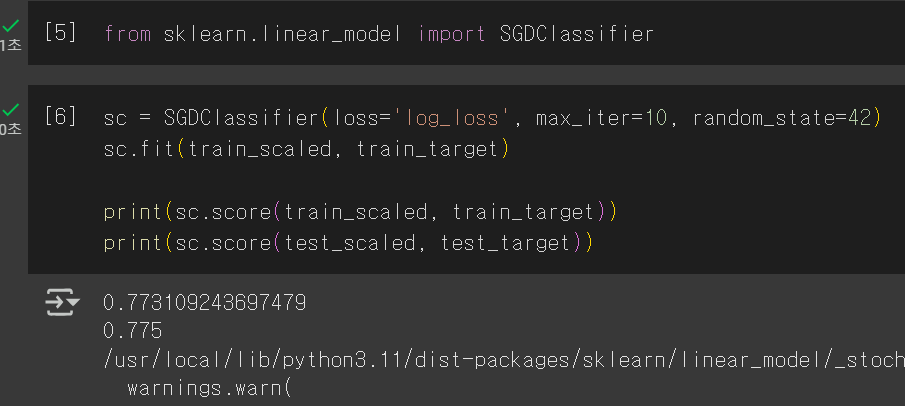
이어서 SGDClassifier 클래스를 사용하면 확률적 경사 하강법을 활용할 수 있다.
✅SGDClassifier : 확률적 경사 하강법을 활용한 분류용 클래스
> loss, max_iter 지정
손실 함수로는 log_loss(로지스틱 손실 함수), 에포크는 10으로 설정하여 학습시켰다.
그리고 정확도를 출력하면 웬 경고 하나가 같이 뜬다............
이 경고는 에포크 수를 늘리면 된다고 한다.
하지만 진짜 그냥 경고이기 때문에 무시해도 상관은 없다. 단지 내가 탄생시키는 모델이 바보가 되는 것 뿐...

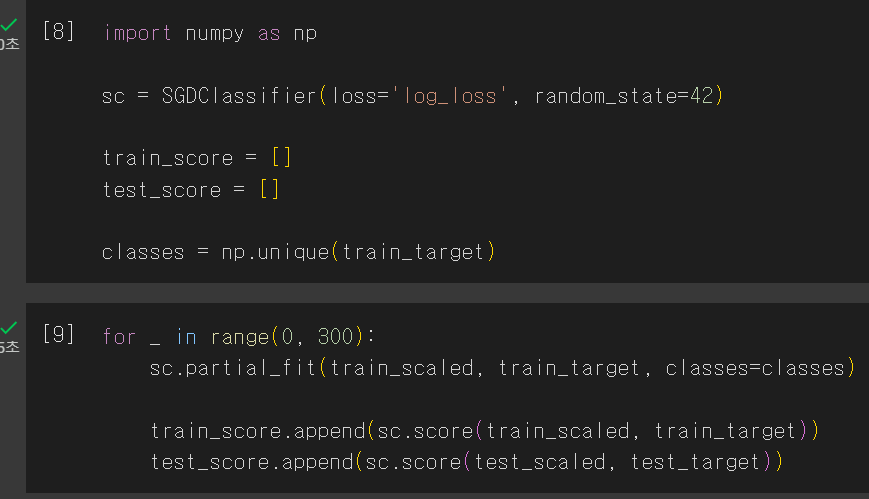
추가 훈련을 시킬때는 partial_fit()을 사용하면 된다.
내가 돌린 결과는 책보다 훨씬 더 높은 정확도가 나오게 되었다.. (뭔진 모르겠지만 일단 대박)
✅partial_fit() : 점진적 학습에서 추가 훈련을 할 때 사용할 수 있다.
확률적 경사 하강법을 사용한 모델은 에포크 수에 따라 과대·과소적합이 될 수 있다.
너무 작아도 안되고 너무 커도 안되니 그 사이의 적절한 에포크 수를 찾는 것이 관건이다..

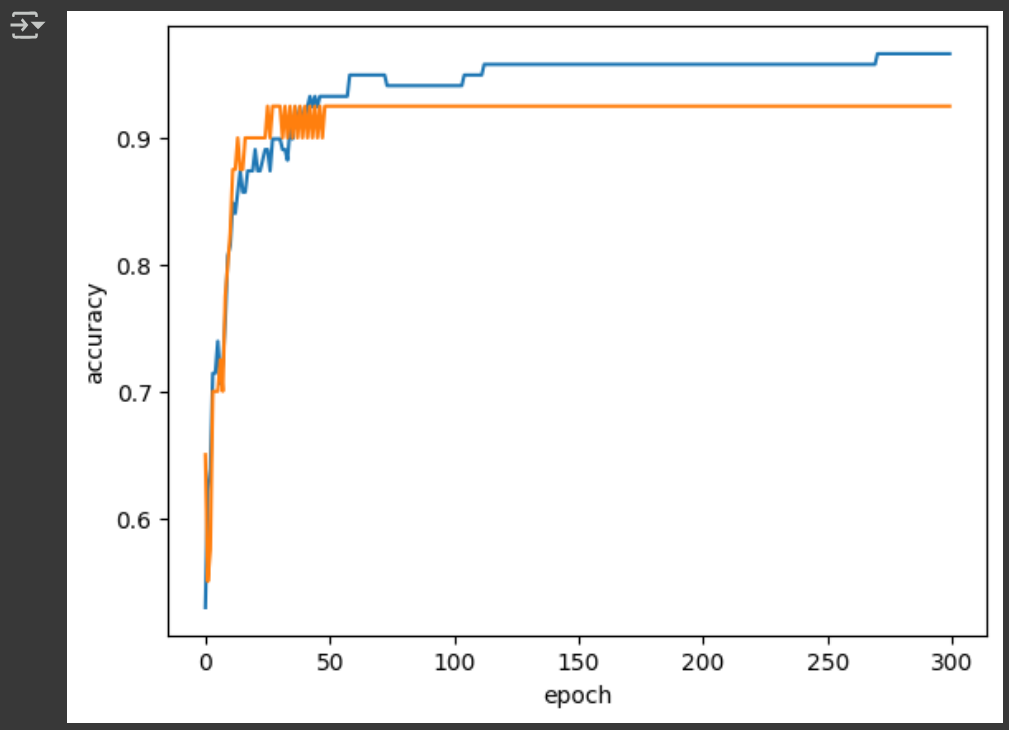
에포크 300으로 추가 학습을 하고 각 에포크마다의 정확도를 나타낸 그래프이다.
초기에는 정확도가 너무 낮고 100 이후로는 커질수록 정확도의 차이가 점점 커지는 것을 볼 수 있다.
따라서 가장 적절한 에포크 수는 100!!!

이를 통해 에포크를 100으로 맞추면 훨씬 높은 정확도가 나오게 된다. 야호!
추가로 tol 파라미터를 설정하면 성능이 향상되지 않을 때 자동으로 학습을 멈춘다.
보통 1e-3으로 설정하는듯??!!
✅tol : 자동으로 학습을 멈출 지 설정
기본 과제 : 4-1 확인문제 2
2. 로지스틱 회귀가 이진 분류에서 확률을 출력하기 위해 사용하는 함수는 무엇인가요?
정답은 ① 시그모이드 함수 !!
시그모이드 함수를 이용해서 z값을 0~1사이의 확률로 변환해서 출력했었죠. 후후
다중 분류에서는 소프트맥스 함수 사용했던 것까지 잊지 않으면 완벽할 것 같습니다!
추가 과제 : 4-2 과대적합 / 과소적합 손코딩 코랩 화면 캡처
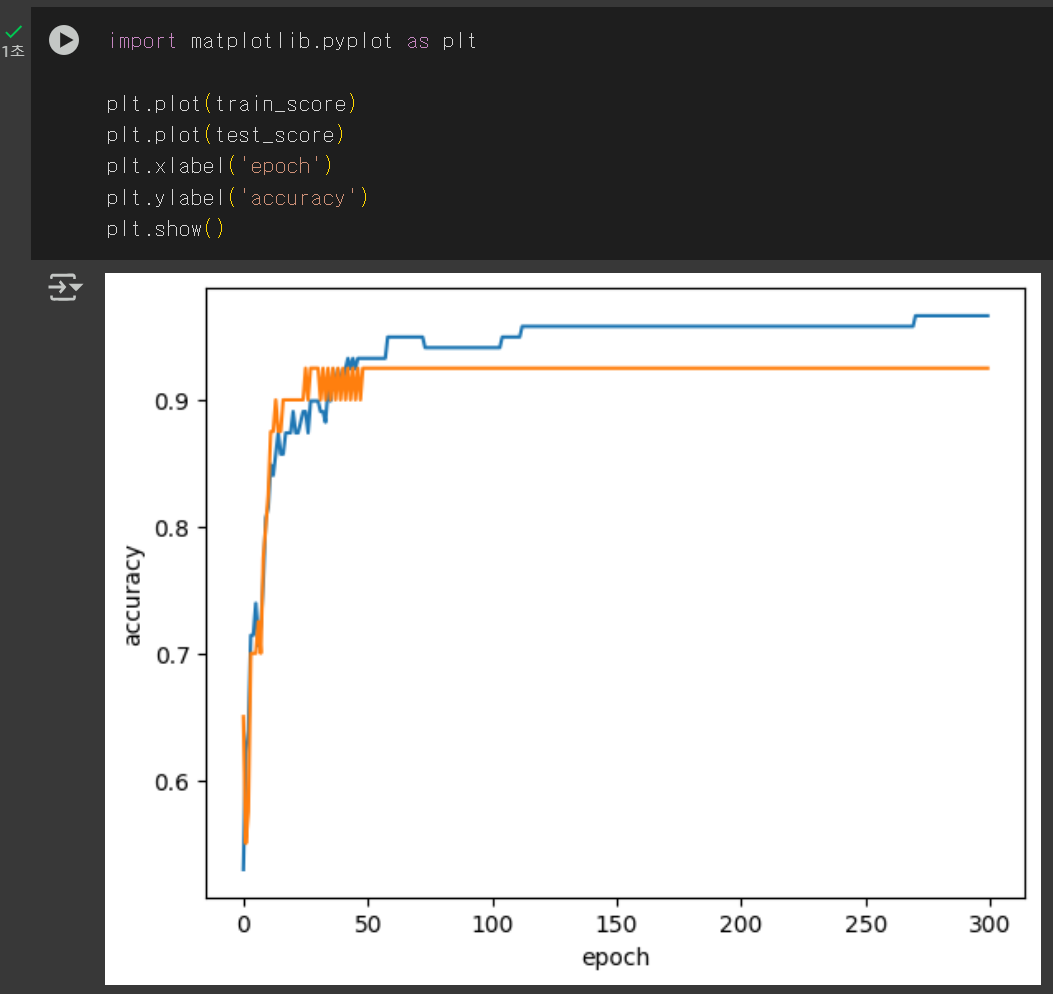
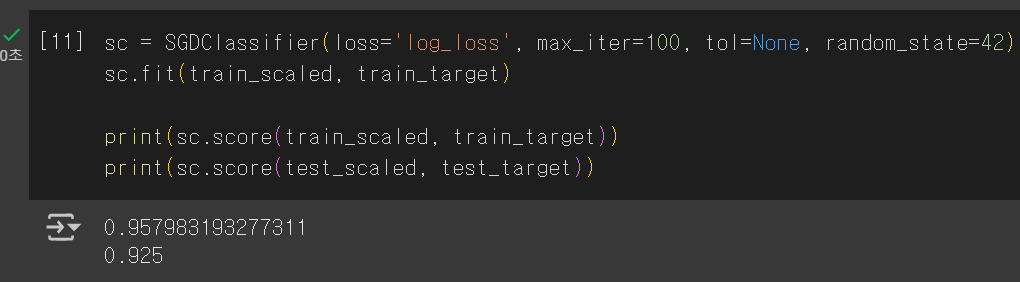
이번 주는 좀 열심히 한 것 같아서 뿌듯하당.
이번 범위 왠지 모르게 수학식이 쏟아져 나온 것 같아서 머리 북북 긁으면서 봄..
점진적 학습이라는 거 미리 알았으면 저번 주 뺑이칠 때 모델 학습 40분씩 안기다려도 됏을텐데...................
어쨋든
다음 주 하루종일 드러누워서 애니도 보고 푹~~~ 쉴 생각에 조커됨 부힛부힛..
다음 주 만큼은 다 잊고 즐기자..
연휴 끝나면 또 BTS급 스케줄 준비되어있음
아 가라고요..

'Machine Learning' 카테고리의 다른 글
| [혼공머신] 6주차_인공 신경망 / 심층 신경망 / 손실 곡선, 드롭아웃, 모델 저장, 콜백 (1) | 2025.02.23 |
|---|---|
| [혼공머신] 5주차_군집 알고리즘 / k-평균, 이너셔 / PCA (7) | 2025.02.16 |
| [혼공머신] 4주차_결정 트리 / 교차 검증 / 앙상블 기법 (2) | 2025.02.09 |
| [혼공머신] 2주차_회귀 / 특성 공학 / 변환기(Transformer) (4) | 2025.01.19 |
| [혼공머신] 1주차_훈련, 테스트 셋 / 데이터 전처리 (3) | 2025.01.07 |